Продолжаем рассказывать о средстве номер 1 StarWind Native SAN для создания отказоустойчивых хранилищ виртуальных машин для серверов Microsoft Hyper-V (тут о последней версии 5.8). Как известно, в средних и больших инфраструктурах серверов Hyper-V для управления хост-серверами и виртуальными машинами используется средство централизованного управления System Center Virtual Machine Manager (SC VMM). Поэтому администраторам хочется управлять серверами хранилищ StarWind непосредственно из консоли SC VMM. Для этого есть специальный компонент StarWind SMI-S Agent:
Поставить его с наскока не получится - нужно сначала прочитать документ "StarWind SMI-S Agent: Storage Provider for SCVMM", где описаны основные шаги установки этого агента и настройки SC VMM. Скачать StarWind SMI-S Agent можно по этой ссылке.
Берлингтон, штат Массачусетс – 7 мая 2012 - StarWind Software Inc., разработчик инновационного программного обеспечения для СХД и резервного копирования виртуальных машин, внесен в список претендентов на награды в конкурсе 2012 Storage Awards (Storries IX) журнала «Storage Magazine» в номинациях «Продукт года в сфере виртуализации хранилищ данных» и «One to Watch». Таги:
Мы уже некоторое время назад писали про различные особенности томов VMFS, где вскользь касалисьпроблемы блокировок в этой кластерной файловой системе. Как известно, в платформе VMware vSphere 5 реализована файловая система VMFS 5, которая от версии к версии приобретает новые возможности.
При этом в VMFS есть несколько видов блокировок, которые мы рассмотрим ниже. Блокировки на томах VMFS можно условно разделить на 2 типа:
Блокировки файлов виртуальных машин
Блокировки тома
Блокировки файлов виртуальных машин
Эти блокировки необходимы для того, чтобы файлами виртуальной машины мог в эксклюзивном режиме пользоваться только один хост VMware ESXi, который их исполняет, а остальные хосты могли запускать их только тогда, когда этот хост вышел из строя. Назвается этот механизм Distributed Lock Handling.
Блокировки важны, во-первых, чтобы одну виртуальную машину нельзя было запустить одновременно с двух хостов, а, во-вторых, для их обработки механизмом VMware HA при отказе хоста. Для этого на томе VMFS существует так называемый Heartbeat-регион, который хранит в себе информацию о полученных хостами блокировок для файлов виртуальных машин.
Обработка лока на файлы ВМ происходит следующим образом:
Хосты VMware ESXi монтируют к себе том VMFS.
Хосты помещают свои ID в специальный heartbeat-регион на томе VMFS.
ESXi-хост А создает VMFS lock в heartbeat-регионе тома для виртуального диска VMDK, о чем делается соответствующая запись для соответствующего ID ESXi.
Временная метка лока (timestamp) обновляется этим хостом каждые 3 секунды.
Если какой-нибудь другой хост ESXi хочет обратиться к VMDK-диску, он проверяет наличие блокировки для него в heartbeat-регионе. Если в течение 15 секунд (~5 проверок) ESXi-хост А не обновил timestamp - хосты считают, что хост А более недоступен и блокировка считается неактуальной. Если же блокировка еще актуальна - другие хосты снимать ее не будут.
Если произошел сбой ESXi-хоста А, механизм VMware HA решает, какой хост будет восстанавливать данную виртуальную машину, и выбирает хост Б.
Далее все остальные хосты ESXi виртуальной инфраструктуры ждут, пока хост Б снимет старую и поставит свою новую блокировку, а также накатит журнал VMFS.
Данный тип блокировок почти не влияет на производительность хранилища, так как происходят они в нормально функционирующей виртуальной среде достаточно редко. Однако сам процесс создания блокировки на файл виртуальной машины вызывает второй тип блокировки - лок тома VMFS.
Блокировки на уровне тома VMFS
Этот тип блокировок необходим для того, чтобы хост-серверы ESXi имели возможность вносить изменения в метаданные тома VMFS, обновление которых наступает в следующих случаях:
Создание, расширение (например, "тонкий" диск) или блокировка файла виртуальной машины
Изменение атрибутов файла на томе VMFS
Включение и выключение виртуальной машины
Создание, расширение или удаление тома VMFS
Создание шаблона виртуальной машины
Развертывание ВМ из шаблона
Миграция виртуальной машины средствами vMotion
Для реализации блокировок на уровне тома есть также 2 механизма:
Механизм SCSI reservations - когда хост блокирует LUN, резервируя его для себя целиком, для создания себе эксклюзивной возможности внесения изменений в метаданные тома.
Механизм "Hardware Assisted Locking", который блокирует только определенные блоки на устройстве (на уровне секторов устройства).
Наглядно механизм блокировок средствами SCSI reservations можно представить так:
Эта картинка может ввести в заблуждение представленной последовательностью операций. На самом деле, все происходит не совсем так. Том, залоченный ESXi-хостом А, оказывается недоступным другим хостам только на период создания SCSI reservation. После того, как этот reservation создан и лок получен, происходит обновление метаданных тома (более длительная операция по сравнению с самим резервированием) - но в это время SCSI reservation уже очищен, так как лок хостом А уже получен. Поэтому в процессе самого обновления метаданных хостом А все остальные хосты продолжают операции ввода-вывода, не связанные с блокировками.
Надо сказать, что компания VMware с выпуском каждой новой версии платформы vSphere вносит улучшения в механизм блокировки, о чем мы уже писали тут. Например, функция Optimistic Locking, появившаяся еще для ESX 3.5, позволяет собирать блокировки в пачки, максимально откладывая их применение, а потом создавать один SCSI reservation для целого набора локов, чтобы внести измененения в метаданные тома VMFS.
С появлением версии файловой системы VMFS 3.46 в vSphere 4.1 появилась поддержка функций VAAI, реализуемых производителями дисковых массивов, так называемый Hardware Assisted Locking. В частности, один из алгоритмов VAAI, отвечающий за блокировки, называется VAAI ATS (Atomic Test & Set). Он заменяет собой традиционный механизм SCSI reservations, позволяя блокировать только те блоки метаданных на уровне секторов устройства, изменение которых в эксклюзивном режиме требуется хостом. Действует он для всех перечисленных выше операций (лок на файлы ВМ, vMotion и т.п.).
Если дисковый массив поддерживает ATS, то традиционная последовательность SCSI-комманд RESERVE, READ, WRITE, RELEASE заменяется на SCSI-запрос read-modify-write для нужных блокировке блоков области метаданных, что не вызывает "замораживания" LUN для остальных хостов. Но одновременно метаданные тома VMFS, естественно, может обновлять только один хост. Все это лучшим образом влияет на производительность операций ввода-вывода и уменьшает количество конфликтов SCSI reservations, возникающих в традиционной модели.
По умолчанию VMFS 5 использует модель блокировок ATS для устройств, которые поддерживают этот механизм VAAI. Но бывает такое, что по какой-либо причине, устройство перестало поддерживать VAAI (например, вы откатили обновление прошивки). В этом случае обработку блокировок средствами ATS для устройства нужно отменить. Делается это с помощью утилиты vmkfstools:
vmkfstools --configATSOnly 0 device
где device - это пусть к устройству VMFS вроде следующего:
Как и ожидалось, компания VMware в самом начале мая объявила о выпуске новой версии решения для виртуализации настольных ПК VMware View 5.1, в которой появилось несколько значимых нововведений и улучшений. Мы уже писали о новой версии View 5.1 (и тут), где был приведен основной список новых возможностей, а в этой статье разберем их подробнее. Основные нововведения VMware View 5.1 перечислены на картинке ниже...
Масштабируемость корпоративного класса, передовые возможности репликации, поддержка нескольких гипервизоров и принципиально новые возможности защиты данных в новом решении Veeam версии 6. Во время вебинара мы расскажем вам о других дополнениях этой версии, отмеченной многочисленными наградами.
Таги:
Сотрудники компании VMware не так давно на корпоративном блоге публиковали заметки о сравнении протоколов FC, iSCSI, NFS и FCoE, которые используются в VMware vSphere для работы с хранилищами. В итоге эта инициатива переросла в документ "Storage Protocol Comparison", который представляет собой сравнительную таблицу по различным категориям, где в четырех столбиках приведены преимущества и особенности того или иного протокола:
Полезная штука со многими познавательными моментами.
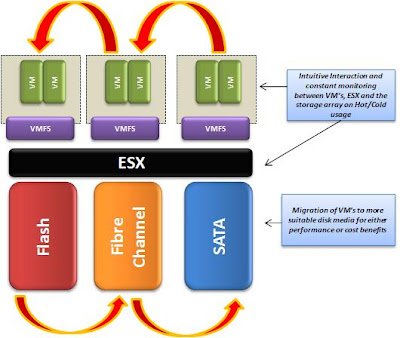
Одним из ключевых нововведений VMware vSphere 5, безусловно, стала технология выравнивания нагрузки на хранилища VMware vSphere Storage DRS (SDRS), которая позволяет оптимизировать нагрузку виртуальных машин на дисковые устройства без прерывания работы ВМ средствами технологии Storage vMotion, а также учитывать характеристики хранилищ при их первоначальном размещении.
Основными функциями Storage DRS являются:
Балансировка виртуальных машин между хранилищами по вводу-выводу (I/O)
Балансировка виртуальных машин между хранилищами по их заполненности
Интеллектуальное первичное размещение виртуальных машин на Datastore в целях равномерного распределения пространства
Учет правил существования виртуальных дисков и виртуальных машин на хранилищах (affinity и anti-affinity rules)
Ключевыми понятими Storage DRS и функции Profile Driven Storage являются:
Datastore Cluster - кластер виртуальных хранилищ (томов VMFS или NFS-хранилищ), являющийся логической сущностью в пределах которой происходит балансировка. Эта сущность в чем-то похожа на обычный DRS-кластер, который составляется из хост-серверов ESXi.
Storage Profile - профиль хранилища, используемый механизмом Profile Driven Storage, который создается, как правило, для различных групп хранилищ (Tier), где эти группы содержат устройства с похожими характеристиками производительности. Необходимы эти профили для того, чтобы виртуальные машины с различным уровнем обслуживания по вводу-выводу (или их отдельные диски) всегда оказывались на хранилищах с требуемыми характеристиками производительности.
При создании Datastore Cluster администратор указывает, какие хранилища будут в него входить (максимально - 32 штуки в одном кластере):
Как и VMware DRS, Storage DRS может работать как в ручном, так и в автоматическом режиме. То есть Storage DRS может генерировать рекомендации и автоматически применять их, а может оставить их применение на усмотрение пользователя, что зависит от настройки Automation Level.
С точки зрения балансировки по вводу-выводу Storage DRS учитывает параметр I/O Latency, то есть round trip-время прохождения SCSI-команд от виртуальных машин к хранилищу. Вторым значимым параметром является заполненность Datastore (Utilized Space):
Параметр I/O Latency, который вы планируете задавать, зависит от типа дисков, которые вы используете в кластере хранилищ, и инфраструктуры хранения в целом. Однако есть некоторые пороговые значения по Latency, на которые можно ориентироваться:
SSD-диски: 10-15 миллисекунд
Диски Fibre Channel и SAS: 20-40 миллисекунд
SATA-диски: 30-50 миллисекунд
По умолчанию рекомендации по I/O Latency для виртуальных машин обновляются каждые 8 часов с учетом истории нагрузки на хранилища. Также как и DRS, Storage DRS имеет степень агрессивности: если ставите агрессивный уровень - миграции будут чаще, консервативный - реже. Первой галкой "Enable I/O metric for SDRS recommendations" можно отключить генерацию и выполнение рекомендаций, которые основаны на I/O Latency, и оставить только балансировку по заполненности хранилищ.
То есть, проще говоря, SDRS может переместить в горячем режиме диск или всю виртуальную машину при наличии большого I/O Latency или высокой степени заполненности хранилища на альтернативный Datastore.
Самый простой способ - это балансировка между хранилищами в кластере на базе их заполненности, чтобы не ломать голову с производительностью, когда она находится на приемлемом уровне.
Администратор может просматривать и применять предлагаемые рекомендации Storage DRS из специального окна:
Когда администратор нажмет кнопку "Apply Recommendations" виртуальные машины за счет Storage vMotion поедут на другие хранилища кластера, в соответствии с определенным для нее профилем (об этом ниже).
Аналогичным образом работает и первичное размещение виртуальной машины при ее создании. Администратор определяет Datastore Cluster, в который ее поместить, а Storage DRS сама решает, на какой именно Datastore в кластере ее поместить (основываясь также на их Latency и заполненности).
При этом, при первичном размещении может случиться ситуация, когда машину поместить некуда, но возможно подвигать уже находящиеся на хранилищах машины между ними, что освободит место для новой машины (об этом подробнее тут):
Как видно из картинки с выбором кластера хранилищ для новой ВМ, кроме Datastore Cluster, администратор первоначально выбирает профиль хранилищ (Storage Profile), который определяет, по сути, уровень производительности виртуальной машины. Это условное деление хранилищ, которое администратор задает для хранилищ, обладающих разными характеристиками производительности. Например, хранилища на SSD-дисках можно объединить в профиль "Gold", Fibre Channel диски - в профиль "Silver", а остальные хранилища - в профиль "Bronze". Таким образом вы реализуете концепцию ярусного хранения данных виртуальных машин:
Выбирая Storage Profile, администратор будет всегда уверен, что виртуальная машина попадет на тот Datastore в рамках выбранного кластера хранилищ, который создан поверх дисковых устройств с требуемой производительностью. Профиль хранилищ создается в отельном интерфейсе VM Storage Profiles, где выбираются хранилища, предоставляющие определенный набор характеристик (уровень RAID, тип и т.п.), которые платформа vSphere получает через механизм VASA (VMware vStorage APIs for Storage Awareness):
Ну а дальше при создании ВМ администратор определяет уровень обслуживания и характеристики хранилища (Storage Profile), а также кластер хранилища, датасторы которого удовлетворяют требованиям профиля (они отображаются как Compatible) или не удовлетворяют им (Incompatible). Концепция, я думаю, понятна.
Регулируются профили хранилищ для виртуальной машины в ее настройках, на вкладке "Profiles", где можно их настраивать на уровне отдельных дисков:
На вкладке "Summary" для виртуальной машины вы можете увидеть ее текущий профиль и соответствует ли в данный момент она его требованиям:
Также можно из оснастки управления профилями посмотреть, все ли виртуальные машины находятся на тех хранилищах, профиль которых совпадает с их профилем:
Далее - правила размещения виртуальных машин и их дисков. Определяются они в рамках кластера хранилищ. Есть 3 типа таких правил:
Все виртуальные диски машины держать на одном хранилище (Intra-VM affinity) - установлено по умолчанию.
Держать виртуальные диски обязательно на разных хранилищах (VMDK anti-affinity) - например, чтобы отделить логи БД и диски данных. При этом такие диски можно сопоставить с различными профилями хранилищ (логи - на Bronze, данны - на Gold).
Держать виртуальные машины на разных хранилищах (VM anti-affinity). Подойдет, например, для разнесения основной и резервной системы в целях отказоустойчивости.
Естественно, у Storage DRS есть и свои ограничения. Основные из них приведены на картинке ниже:
Основной важный момент - будьте осторожны со всякими фичами дискового массива, не все из которых могут поддерживаться Storage DRS.
И последнее. Технологии VMware DRS и VMware Storage DRS абсолютно и полностью соместимы, их можно использовать совместно.
Компания Veeam Software, известная своим продуктом для резервного копирования Veeam Backup and Replication, выпустила финальную версию решения Veeam ONE v6, предназначенного для мониторинга (бывший продукт Veeam Monitor), а также контроля изменений и автоматизированной отчетности (бывший продукт Veeam Reporter) виртуальных инфраструктур VMware vSphere и Microsoft Hyper-V. О новом комплекте поставки решения Veeam ONE мы уже писали тут и тут.
Функции мониторинга:
Функции отчетности:
Теперь два продукта Veeam Reporter и Monitor работают на одном движке с общей базой данных, что делает Veeam ONE законченным решением для управления виртуальной инфраструктурой с точки зрения мониторинга, отчетности, контроля изменений и планирования мощностей. Все в одном.
Новые возможности Veeam ONE v6:
Мониторинг
New monitoring views - новые представления дэшбордов summary, alarm и resource, позволяющие осуществлять быструю навигацию вглубь объектов.
Read-only access to monitoring clients - для клиентов, которым нужны только функции наблюдения за виртуальной средой, можно ограничить права на изменения объектов.
Logical groupings of performance counters - пользователь несколькими кликами может поместить на графики метрики различных категорий для отслеживания возможных зависимостей между ними.
Детализация
Detailed views - для многих объектов можно "проваливаться" вниз с максимальным уровнем детализации.
Child object status display - индикаторы статуса родительских объектов дают представление о том, что происходит с дочерними, и какие у них могут быть проблемы.
Generating reports from widgets - с помощью виджетов в Veeam ONE можно быстро сгенерировать отчет, отражающий заданный период времени.
Тревоги (Alarms)
New alarms - теперь еще большее количество алармов.
Default action - при срабатывании аларма автоматически посылается нотификация по почте всем, кто находится в группе default notification group.
Filtering - фильтры по тревогам могут быть основаны на базе error level, status, object type и времени.
Exclusions - исключения для алармов, которые можно применить к различным объектам: виртуальным дискам, сенсорам оборудования на хостах и т.п.
Email customization - редактирование поля subject и формата нотификаций.
Configurable email notification groups - можно задавать, кто получает нотификации по группам событий.
Отчетность
Overview reports - отчеты по Storage capacity, storage usage, а также обзорные отчеты infrastructure, hypervisor,
clusters и VMs.
Monitoring reports - отчеты по мониторингу: Alarms, uptime ВМ, производительность кластера, хостов и виртуальных машин, включая отчет по потребителям наибольшего количества ресурсов.
(VMware only) Optimization reports - ВМ с перевыделенными или недовыделенными ресурсами, снапшотами, лишними файлами, а также простаивающие ВМ и шаблоны, выключенные ВМ.
(VMware only) Change tracking reports - отслеживание изменений в настройках пользователем или объектом, а также изменения пермиссий.
Integration - дэшборды можно встраивать в письма оповещений, веб-порталы и сторонние приложения.
Access control - для доступа к дэшбордам могут быть заданы разрешения для пользователей.
Автоматическое обновление и бизнес-категоризация
Automatic updates - по запросу Veeam ONE v6 проверяет и загружает обновления репорт-паков, дэшбордов и виджетов.
Business views - представления мониторинга и отчетности могут быть настроены в соответствии с категоризацией, заданной пользователем. Т.е. эти представления можно сделать на основе бизнес или географических критериев.
Standalone hosts - отдельно стоящие хост-серверы также включаются в категоризацию.
Sample categorization - схема бизнес-категоризации, которая показывает пример, как это делать.
Сбор данных в виртуальной среде
Automatically triggered data collection - после установки Veeam ONE сразу же начинается периодический сбор данных с хост-серверов.
Controlled query load - данные о производительности и конфигурации собираются в различных задачах, что позволяет более гибко подходить к распределению нагрузки этими задачами на хост-серверы.
Granular performance history - в Veeam ONE v6 сохраняется гранулярная история производительности за длительный промежуток времени, включающая в себя данные мониторинга и отчетности.
Поддержка VMware vSphere 5
Datastore maximum queue depth - Veeam ONE v6 включает эту новую метрику vSphere 5.
Storage clusters - мониторинг и оповещения по кластерам хранилищ vSphere 5.
Поддержка Microsoft Hyper-V
Alarms - Veeam ONE имеет 90 алармов для хостов и других объектов Hyper-V.
Full monitoring support for Failover Clusters - для кластеров Hyper-V поддерживаются все функции мониторинга, включая алармы, отчеты, чарты и статьи базы знаний для томов CSV.
Direct collection of performance data - данные о производительности собираются напрямую с хост-серверов, включая хосты без SC VMM, что позволяет контролировать больше, чем сам SC VMM.
Решение Veeam ONE v6 для Microsoft Hyper-V и VMware vSphere можно скачать по одной ссылке тут.
На днях появилась бета-версия продукта StarWind iSCSI SAN 5.9, средства номер 1 для создания отказоустойчивых хранилищ iSCSI под виртуальные машины VMware vSphere и Microsoft Hyper-V. Традиционно, несмотря на то что версия StarWind 5.8 вышла совсем недавно, нас ожидает множество нововведений и улучшений. Данная версия пока для VMware, под Hyper-V (Native SAN) выйдет немного позже.
Итак, новые возможности StarWind iSCSI 5.9, доступные в бете:
1. Трехузловой кластер высокой доступности хранилищ, еще больше повышающий надежность решения. При этом все три узла являются активными и на них идет запись. Диаграмма:
По обозначенным трем каналам синхронизации данные хранилищ синхронизируются между собой. Также все узлы обмениваются друг с другом сигналами доступности (Heartbeat).
2. Репликация на удаленный iSCSI Target через WAN-соединение с поддержкой дедупликации. Эта функция пока экспериментальная, но данная возомжность часто требуется заказчиками для катастрофоустойчивых решений хранилищ.
3. Поддержка механизмом дедупликации данных, которые удаляются с хранилищ - неиспользуемые блоки перезаписываются актуальными данными.
4. Использование памяти механизмом дедупликации сократилось на 30%. Теперь необходимо 2 МБ памяти на 1 ГБ дедуплицируемого хранилища при использовании блока дедупликациии 4 КБ.
5. StarWind SMI-S agent, доступный для загрузки как отдельный компонент. Он позволяет интегрировать StarWind в инфраструктуру Systme Center Virtual Machine Manager (SC VMM), добавив StarWind Storage Provider, реализующий задачи управления таргетами и хранилищами.
6. Как пишут на форуме, появилась полноценная поддержка механизма ALUA, работа с которым идет через SATP-плагин VMW_SATP_ALUA (подробнее об этом тут).
Скачать бета версию StarWind iSCSI SAN 5.9 можно по этой ссылке.
В преддверии выхода новой версии платформы для виртуализации настольных ПК VMware View 5.1, о котором будет объявлено 3 мая, продолжаем рассказывать о новых возможностях этого продукта. Сегодня продолжим разговор о функции Content Based Read Cache (CBRC), которая позволяет увеличить производительность операций чтения для наиболее часто читаемых блоков виртуальных ПК.
Как мы уже писали ранее, Content Based Read Cache - это функция кэширования в оперативной памяти хоста VMware ESXi, которая уже реализована в VMware vSphere 5. Убедиться в этом вы можете сами, открыв Advanced Settings на хосте:
Как мы видим из картинки, есть планка для CBRC размером в 2 ГБ, которую нельзя менять и есть текущее значение памяти, зарезервированной для кэша. Кроме того, есть настройка таймаута при загрузке хоста для дайджест-журнала SCSI, который хранит в себе хэш-таблицу блоков, которые учитывает кэш CBRC при их запросе от виртуальной машины.
Этот дайджест хранится в папке с виртуальной машиной в виде отдельного VMDK-файла:
То есть, при чтении виртуальной машиной блока с хранилища, он сначала ищется в кэше, и, если он там отсутствует, то он туда помещается и отдается виртуальной машине. Ну а если он в кэше есть - то сразу ей отдается. Соответственно, кэш CBRC увеличивает производительность при операциях чтения виртуальных машин хоста с одними и теми же блоками, что часто бывает в инфраструктуре VDI. Особенно это актуально при одновременной загрузке десятков виртуальных ПК, которая может вызвать так называемый Boot Storm. Посмотрите, как увеличивается интенсивность операций чтения при загрузке Windows ВМ, с которую может существенно "погасить" CBRC:
Надо отметить, что CBRC - это чисто хостовая фишка VMware vSphere, которую может поддерживать любое надстроенное VDI-решение (например, Citrix XenDesktop). А вот в VMware View поддержка CBRC будет идти под эгидой функции VMware View Storage Accelerator:
Как понятно из описанного выше, для такой поддержки практически ничего уже и делать не нужно - все есть в ESXi 5.0.
Во второй части заметки рассмотрим возможность VMware View Client Side Caching, которая представляет собой использование кэша в оперативной памяти устройств доступа к виртуальным ПК (тонкие и толстые клиенты с View Client) для картинки рабочего стола (а точнее, ее регионов). Эта возможность появилась уже в VMware View 5.0 и включена по умолчанию: 250 МБ памяти используется на клиенте, за исключением всяких Android и iOS-устройств.
Представьте, что вы просматриваете в виртуальном ПК PDF-документ. Рамка и контролы в ридере остаются на месте, а его содержимое скроллится в ограниченной области экрана. Вот для этого и нужен Client Side Caching - он позволяет закэшировать этот неизменяющийся фрагмент картинки экрана и не обращаться за ним к хосту и хранилищу. Это увеличивает производительность виртуального ПК до 30%.
Настраивается это просто - через шаблон групповой политики pcoip.adm, про работу с которым написано, например, вот тут. Настройка GPO называется "Configure PCoIP client image cache size policy":
Диапазон допустимых значений - от 50 до 300 МБ. Работает эта штука и для Linux-устройств. С ней есть тоже одна засада - если на тонком клиенте мало оперативной памяти (меньше 1 ГБ), клиентский кэш луше немного уменьшить, если наблюдаются проблемы с производительностью.
Подолжаем вас знакомить с решением номер 1 для создания отказоустойчивых хранилищ iSCSI серверов VMware ESXi и Microsoft Hyper-V - StarWind iSCSI. Как мы уже писали, недавно вышла новая версия StarWind Enterprise 5.8, предоставляющая еще больше возможностей для виртуальных машин, в частности, Hyper-V Backup Plugin и улучшения механизма дедупликации (полный список новинок).
При эксплуатации виртуальной инфраструктуры VMware vSphere иногда случается ситуация, когда виртуальную машину нельзя включить из-за того, что ее какой-нибудь из ее файлов оказывается залоченным. Происходит это при разных обстоятельствах: неудачной миграции vMotion / Storage vMotion, сбоях в сети хранения и прочих.
Наиболее распространенная ошибка при этом выглядит так:
Could not power on VM: Lock was not free
Встречаются также такие вариации сообщений и ошибок при попытке включения виртуальной машины, которое зависает на 95%:
Unable to open Swap File
Unable to access a file since it is locked
Unable to access a file <filename> since it is locked
Unable to access Virtual machine configuration
Ну а при попытке соединения с консолью ВМ получается вот такое:
Error connecting to <path><virtual machine>.vmx because the VMX is not started
Все это симптомы одной проблемы - один из следующих файлов ВМ залочен хост-сервером VMware ESXi:
<VMNAME>.vswp
<DISKNAME>-flat.vmdk
<DISKNAME>-<ITERATION>-delta.vmdk
<VMNAME>.vmx
<VMNAME>.vmxf
vmware.log
При этом залочил файл не тот хост ESXi, на котором машина зарегистрирована. Поэтому решение проблемы в данном случае - переместить ВМ холодной миграций на тот хост, который залочил файл и включить ее там, после чего уже можно переносить ее куда требуется. Но как найти тот хост ESXi, который залочил файл? Об этом и рассказывается ниже.
Поиск залоченного файла ВМ
Хорошо если в сообщении при запуске виртуальной машины вам сообщили, какой именно из ее файлов оказался залоченным (как на картинке выше). Но так бывает не всегда. Нужно открыть лог vmware.log, который расположен в папке с виртуальной машиной, и найти там строчки вроде следующих:
Failed to initialize swap file : Lock was not free
Тут видно, что залочен .vswp-файл ВМ.
За логом на экране можно следить командой (запустите ее и включайте ВМ):
tail /vmfs/volumes/<UUID>/<VMDIR>/vmware.log
Проверка залоченности файла ВМ и идентификация владельца лока
После того, как залоченный файл найден, нужно определить его владельца. Сначала попробуем команду touch, которая проверяет, может ли бы обновлен time stamp файла, т.е. можно ли его залочить, или он уже залочен. Выполняем следующую команду:
# touch /vmfs/volumes/<UUID>/<VMDIR>/<filename>
Если файл уже залочен, мы получим вот такое сообщение для него:
В значении "owner" мы видим MAC-адрес залочившего файл хоста VMware ESXi (выделено красным). Ну а как узнать MAC-адрес хоста ESXi - это вы должны знать. Дальше просто делаем Cold Migration виртуальной машины на залочивший файл хост ESXi и включаем ее там.
Те, кто хочет дальше изучать вопрос, могут проследовать в KB 10051.
Однако вышедший Microsoft Virtual Machine Converter - это единственное поддерживаемое со стороны MS решение для конверсии VMDK2VHD на платформу Hyper-V. Само собой, конвертируется не только виртуальный диск, но и вся машина в целом.
Конвертация виртуальной машины происходит с простоем ВМ, так как MVMC делает ее снапшот, сносит VMware Tools и драйверы, затем копирует исходный виртуальный диск, после чего откатывает снапшот ВМ.
Microsoft Virtual Machine Converter поддерживает V2V-конвертацию виртуальных машин со следующих платформ VMware:
VMware vSphere 5.0 (vCenter / ESX / ESXi 5.0)
VMware vSphere 4.1 (vCenter / ESX / ESXi 4.1)
В качестве хоста назначения могут быть использованы следующие платформы:
Windows Server 2008 R2 SP1 с ролью Hyper-V (+ Server Core)
Hyper-V Server 2008 R2 SP1
Для конвертации поддерживаются следующие гостевые ОС:
Windows Server 2003 SP2 Web, Standard, Enterprise и Datacenter (x86+x64)
Windows 7 Enterprise (x86+x64)
Windows Server 2008 R2 SP1 Web, Standard, Enterprise, Datacenter.
Поддержка семейства Windows Server 8 в бета-версии MVMC отсутствует. Документацию по Microsoft Virtual Machine Converter можно загрузить по этой ссылке. Тем, кому необходима P2V-миграция от Microsoft, следует использовать Microsoft P2V Migration Tool.
На блоге vMind.ru уже писали о просочившихся в интернет подробностях о новых возможностях решения для виртуализации настольных ПК VMware View 5.1, а мы сегодня осветим еще несколько интересных моментов.
Большинство нововведений VMware View 5.1 показаны на этом слайде:
Основная новая функция - это, конечно же, VMware View Storage Accelerator, которая позволяет использовать оперативную память сервера для кэширования наиболее часто используемых блоков данных виртуальных ПК, запрашиваемых с конечного устройства. Делается это средствами технологии Content Based Read Cache (CBRC), поддержка которой уже имеется в VMware vSphere 5.0. Эта штука, само собой, положительно влияет на скорость обмена данными с конечными устройствами и производительность операций ввода-вывода для виртуальных ПК, поскольку блоки запрашиваются напрямую из памяти:
Этот тест проводился для 50 виртуальных ПК с гостевой ОС Windows 7 и были достигнуты следующие результаты:
Увеличение до 80% пиковых IOPS
Увеличение на 45% средних IOPS
Увеличение пиковой скорости обмена с ПК до 65%
Увеличение средней скорости обмена с ПК на 25%
Настройки кэширования на хосте ESXi задаются в конфигурации VMware View Manager 5.1:
При этом, как и всегда, данная техника оптимизации полностью прозрачна для виртуальных машин, средств управления и прочего.
Полный список нововведений VMware View 5.1:
Расширенные техники по оптимизации хранилищ и интеграции с устройствами хранения:
View Storage Accelerator: использование локального кэша Content Based Read Cache (CBRC) на хосте vSphere 5.0
View Composer API Integration (находится в стадии Tech Preview): теперь операции по клонированию десктопов в View Composer используют технологию vStorage API for Array Integration (VAAI) Native Cloning для дисковых массивов NAS. Это позволит ускорить развертывание виртуальных ПК.
В View Composer можно будет задавать букву диска в гостевой ОС для disposable disk (своп и временные файлы)
Поддержка до 32-х (вместо 8) хостов в кластере, когда используется NAS-хранилище
Улучшенная поддержка USB-устройств, т.е. подключаемые к оконечному ПК устройства новых моделей (планшеты, камеры и т.п.) будут видны в виртуальном ПК
Поддержка двухфакторной аутентификации Radius
Улучшения административного интерфейса View Manager
Поддержка аккаунтов ПК в Active Directory, которые были созданы перед внедрением View
Программа VMware по улучшению качества работы в виртуальных ПК
Поддержка виртуальных профилей (Virtual Profiles) для физических ПК
Использование возможностей виртуальных профилей как средства миграции десктопа в виртуальную машину
Поддержка установки сервера View Composer на отличный от vCenter сервер
Теперь, что касается даты выхода VMware View 5.1. Анонсировано решение будет 2-3 мая (согласно информации CRN), а доступно для загрузки будет уже 9 мая. При этом VMware View 5.1 будет включать в себя vCenter Operations for View, который будет доступен как аддон за дополнительные деньги.
Ключевые особенности продукта от Symantec - возможность динамической балансировки запросов ввода-вывода с хоста по нескольким путям одновременно, поддержка работы с основными дисковыми массивами, представленными на рынке, и возможность учитывать характеристики хранилищ (RAID, SSD, Thin Provisioning).
Как можно узнать из нашей статьи про PSA, Veritas Dynamic Multi-Pathing (DMP) - это MPP-плагин для хостов ESXi:
Veritas DMP позволяет интеллектуально балансировать нагрузку с хостов ESXi в SAN, обеспечивать непрерывный мониторинг и статистику по путям в реальном времени, автоматически восстанавливать путь в случае сбоя и формировать отчетность через плагин к vCenter обо всех хранилищах в датацентре. Что самое интересное - это можно будет интегрировать с физическим ПО для доступа по нескольким путям (VxVM) в единой консоли.
Всего в Veritas DMP существует 7 политик для балансировки I/O-запросов, которые могут быть изменены "на лету" и позволят существенно оптимизировать канал доступа к хранилищу по сравнению со стандартным плагином PSP от VMware. Кстати, в терминологии Symantec, этот продукт называется - VxDMP.
Стоимость этой штуки - от 900 долларов за четырехъядерный процессор хоста (цена NAM). Полезные ссылки:
Мы недавно писали о новых возможностях продукта для создания отказоустойчивых iSCSI-хранилищ StarWind 5.8 (а тут можно почитать про производительность), а завтра вы можете лично убедиться в превосходстве StarWind над конкурентами и над тем, когда его у вас нет. Для этого завтра надо прийти на вебинар, тем более, что докладчик - наш с вами знакомый, Анатолий Вильчинский из Киева:
Как знают администраторы VMware vSphere в крупных компаниях, в этой платформе виртуализации есть фреймворк, называющийся VMware Pluggable Storage Architecture (PSA), который представляет собой модульную архитектуру работы с хранилищами SAN, позволяющую использовать ПО сторонних производителей для работы с дисковыми массивами и путями.
Выглядит это следующим образом:
А так понятнее:
Как видно из второй картинки, VMware PSA - это фреймворк, работа с которым происходит в слое VMkernel, отвечающем за работу с хранилищами. Расшифруем аббревиатуры:
VMware NMP - Native Multipathing Plug-In. Это стандартный модуль обработки ввода-вывода хоста по нескольким путям в SAN.
Third-party MPP - Multipathing plug-in. Это модуль стороннего производителя для работы по нескольким путям, например, EMC Powerpath
VMware SATP - Storage Array Type Plug-In. Это часть NMP от VMware (подмодуль), отвечающая за SCSI-операции с дисковым массивом конкретного производителя или локальным хранилищем.
VMware PSP - Path Selection Plug-In. Этот подмодуль NMP отвечает за выбор физического пути в SAN по запросу ввода-вывода от виртуальной машины.
Third-party SATP и PSP - это подмодули сторонних производителей, которые исполняют означенные выше функции и могут быть встроены в стандартный NMP от VMware.
MASK_PATH - это модуль, который позволяет маскировать LUN для хоста VMware ESX/ESXi. Более подробно о работе с ним и маскировании LUN через правила написано в KB 1009449.
Из этой же картинки мы можем заключить следующее: при выполнении команды ввода-вывода от виртуальной машины, VMkernel перенаправляет этот запрос либо к MPP, либо к NMP, в зависимости от установленного ПО и обращения к конкретной модели массива, а далее он уже проходит через подуровни SATP и PSP.
Уровень SATP
Это подмодули, которые обеспечивают работу с типами дисковых массивов с хоста ESXi. В составе ПО ESXi есть стандартный набор драйверов, которые есть под все типы дисковых массивов, поддерживаемых VMware (т.е. те, что есть в списке совместимости HCL). Кроме того, есть универсальные SATP для работы с дисковыми массивами Active-active и ALUA (где LUN'ом "владеет" один Storage Processor, SP).
Каждый SATP умеет "общаться" с дисковым массивом конкретного типа, чтобы определить состояние пути к SP, активировать или деактивировать путь. После того, как NMP выбрал нужный SATP для хранилища, он передает ему следующие функции:
Мониторинг состояния каждого из физических путей.
Оповещение об изменении состояний путей
Выполнение действий, необходимый для восстановления пути (например failover на резервный путь для active-passive массивов)
Посмотреть список загруженных SATP-подмодулей можно командой:
esxcli nmp satp list
Уровень PSP
Path Selection Plug-In отвечает за выбор физического пути для I/O запросов. Подмодуль SATP указывает PSP, какую политику путей выставить для данного типа массива, в зависимости от режима его работы (a-a или a-p). Вы можете переназначить эту политику через vSphere Client, выбрав пункт "Manage Paths" для устройства:
Для LUN, презентуемых с массивов Active-active, как правило, выбирается политика Fixed (preferred path), для массивов Active-passive используется дефолтная политика Most Recently Used (MRU). Есть также и еще 2 политики, о которых вы можете прочитать в KB 1011340. Например, политика Fixed path with Array Preference (VMW_PSP_FIXED_AP) по умолчанию выбирается для обоих типов массивов, которые поддерживают ALUA (EMC Clariion, HP EVA).
Надо отметить, что сторонний MPP может выбирать путь не только базовыми методами, как это делает VMware PSP, но и на базе статистического интеллектуального анализа загрузки по нескольким путям, что делает, например, ПО EMC Powerpath. На практике это может означать рост производительности доступа по нескольким путям даже в несколько раз.
Работа с фреймворком PSA
Существуют 3 основных команды для работы с фреймворком PSA:
esxcli, vicfg-mpath, vicfg-mpath35
Команды vicfg-mpath и vicfg-mpath35 аналогичны, просто последняя - используется для ESX 3.5. Общий список доступных путей и их статусы с информацией об устройствах можно вывести командой:
vicfg-mpath -l
Через пакет esxcli можно управлять путями и плагинами PSA через 2 основные команды: corestorage и nmp.
Надо отметить, что некоторые команды esxcli работают в интерактивном режиме. С помощью nmp можно вывести список активных правил для различных плагинов PSA (кликабельно):
esxcli corestorage claimrule list
Есть три типа правил: обычный multipathing - MP (слева), FILTER (аппаратное ускорение включено) и VAAI, когда вы работаете с массивом с поддержкой VAAI. Правила идут в порядке возрастания, с номера 0 до 101 они зарезервированы VMware, пользователь может выбирать номера от 102 до 60 000. Подробнее о работе с правилами можно прочитать вот тут.
Правила идут парами, где file обозначает, что правило определено, а runtime - что оно загружено. Да, кстати, для тех, кто не маскировал LUN с версии 3.5. Начиная с версии 4.0, маскировать LUN нужно не через настройки в vCenter на хостах, а через объявление правил для подмодуля MASK_PATH.
Для вывода информации об имеющихся LUN и их опциях в формате PSA можно воспользоваться командой:
esxcli nmp device list
Можно использовать всю ту же vicfg-mpath -l.
Ну а для вывода информации о подмодулях SATP (типы массивов) и PSP (доступные политики путей) можно использовать команды:
esxcli nmp satp list
esxcli nmp psp list
Ну а дальше уже изучайте, как там можно глубже копать. Рекомендуемые документы:
Как знают все администраторы VMware vSphere, виртуальный диск виртуальной машины представляется как минимум в виде двух файлов:
<имя ВМ>.vmdk - заголовочный, он же индексный, он же файл-дескриптор виртуальго диска, который содержит информацию о геометрии диска, его тип и другие метаданные
<имя ВМ>-flat.vmdk - непосредственно диск с данными ВМ
Практика показывает, что нередки ситуации, когда администраторы VMware vSphere теряют заголовочный файл VMDK по некоторым причинам, иногда необъяснимым, и остается только диск с данными ВМ (неудивительно, ведь в него идет запись, он залочен).
Ниже приведена краткая процедура по восстановлению дескрипторного VMDK-файла для существующего flat-VMDK, чтобы восстановить работоспособность виртуальной машины. Подробную инструкцию можно прочитать в KB 1002511.
Итак, для тех, кто любит смотреть видеоинструкции:
Для тех, кто не любит:
1. Определяем точный размер в байтах VMDK-диска с данными (чтобы геометрия нового созданного дескриптора ему соответствовала):
ls -l <имя диска>-flat.vmdk
2. Создаем новый виртуальный диск (цифры - это полученный размер в байтах, тип thin для экономии места, lsilogic - контроллер):
vmkfstools -c 4294967296 -a lsilogic -d thin temp.vmdk
3. Переименовываем дескрипторный VMDK-файл созданного диска в тот файл, который нам нужен для исходного диска. Удаляем только что созданный пустой диск данных, который уже не нужен (temp-flat.vmdk).
Схема очень проста - StarWind iSCSI можно использовать как для продуктивного хранилища, так и для хранилища резервных копий:
В документе рассматривается вариант использования отказоустойчивого iSCSI-хранилища StarWind в производственной среде, где применяются такие возможности StarWind как:
Снапшоты хранилищ
Дедупликация
Отказоустойчивая конфигурация из двух серверов хранения, обеспечивающая непрерывную работу виртуальных машин в случае отказа одного из них
Компания VMware 2 апреля выпустила клиент для своей новой платформы облачного хранения данных, который доступен для скачивания с Apple Store: VMware Octopus Client для iPad и iPhone.
Напомним, что VMware Project Octopus - это некий аналог Dropbox от VMware, предлагающий функции не только для хранения документов предприятий, но и функции совместной работы, а также имеющий встроенные средства обеспечения безопасности. Об этом проекте мы уже писали тут и тут.
Octopus будет интегрирован со следующими продуктами VMware: Zimbra Collaboration Server for Web-based applications (средства совместной работы), VMware View (использование общих данных в виртуальных ПК), VMware Horizon (управление данными приложений из корпоративного каталога) и AppBlast (доставка приложений через веб-браузер с поддержкой HTML 5 - то есть, открыл браузер - а там каталог приложений, выбираешь - и приложение открывается как будто установленное).
Выглядит это очень похоже на Dropbox:
Что касается модели потребления услуг VMware Octopus, то, как рассказала VMware, это решение можно развернуть как в датацентре своей организации, так и воспользоваться услугами сервис-провайдеров, предоставляющих услуги по программе VSPP.
Надо отметить, что свободной регистрации для использования продукта пока нет, но можно запросить доступ к preview-версии на сайте www.vmwareoctopus.com.
В первой части статьи "Сравнение производительности StarWind iSCSI Enterprise и Microsoft iSCSI" мы приводили выводы Джейка Ратски о том, что iSCSI-таргет от компании StarWind показывает большую производительность по сравнению с его аналогом от Microsoft для рассмотренной нагрузки при установке одной ВМ. Теперь Джейк провел тестирование обоих продуктов при использовании трех виртуальных машин (на той же самой конфигурации оборудования), с которым можно ознакомиться в следующих статьях:
Для тех, кто использует хранилища iSCSI под виртуальные машины - очень полезно ознакомиться. Приведем основные выводы.
1. Использование полосы пропускания адаптера iSCSI.
Microsoft iSCSI:
StarWind iSCSI:
Как видно из картинок, StarWind iSCSI потихоньку разгоняется и показывает лучшие результаты, чем Microsoft iSCSI Target. Происходит это за счет активного использования кэша на сервере хранилища iSCSI, как и в предыдущем тесте:
2. Эффективность процесса дедупликации.
Как мы уже писали, StarWind iSCSI использует inline-дедупликацию данных на хранилище с размером блока 4 КБ, что подразумевает запись на диск только оригинальных копий данных, без повторяющихся блоков. В тесте для 3-х ВМ размером 9 ГБ каждая на хранилище было реально занято 8,69 ГБ данных, что довольно эффективно для трех практически одинаковых машин.
Коэффициент дедупликации - 3.15 к 1.
3. Производительность хранилища.
В тесте опять использовалась нагрузка, генерируемая IOMeter, на одной машине при двух простаивающих, а также на всех трех одновременно. Результат MS iSCSI (нагружена только одна ВМ):
Результат StarWind iSCSI:
И тут снова StarWind выигрывает.
Теперь метрики IOMeter для трех одновременно нагруженных ВМ для Microsoft iSCSI (минута с момента начала генерации нагрузки):
Как знают пользователи виртуализации от Microsoft, в средстве управления System Center Virtual Machine Manager 2008 R2 имелась функция Performance and Resource Optimization (PRO), которая позволяла осуществлять балансировку нагрузки на хост-серверы виртуальной инфраструктуры Hyper-V. Происходит это путем горячей миграции виртуальных машин с загруженных на незагруженные хосты, за счет использования пороговых значений на хостах, задаваемых пользователем (т.е. превышение лимитов памяти или утилизации процессора). По-сути, это аналог VMware DRS в VMware vSphere (и даже Storage DRS, поскольку через партнерские решения могут отслеживаться параметры производительности хранилищ). Миграция виртуальных машин в соответствии с рекомендациями PRO может проводиться автоматически или вручную:
Большим недостатком данной технологии было то, что она требовала наличия продукта System Center Operations Manager, который есть далеко не у всех СМБ-пользователей.
В System Center Virtual Machine Manager 2012 технология PRO была заменена на техники Dynamic Optimization и Power Optimization, которые уже, к счастью, не зависят от Operations Manager и не требуют его. Также появились функции Power Optimization, которые позволяют отключать хост-серверы Hyper-V с малой нагрузкой, за счет миграции с них виртуальных машин (также по пороговым значениям, задаваемым пользователем), в целях экономии электроэнергии (аналог VMware Distributed Power Management, который является частью технологии DRS).
Dynamic Optimization и Power Optimization в SC VMM 2012 позволяют нам настроить следующие параметры:
Степерь агрессивности Dynamic Optimization при применении рекомендаций в кластере или группе хостов (Host group)
Автоматический или ручной режим работы
Интервал между генерациями и применением рекомендаций (по умолчанию 10 минут)
Использовать или нет Power Optimization
Окно (промежуток времени в течение суток), в котое Power Optimization будет работать
Так выглядят настройки Dynamic Optimization:
Пользователь определяет минимальные значения доступных ресурсов при размещении виртуальных машин на хостах:
Обратите, внимание, что пороговые значения могут быть заданы и для Disk I/O, т.е. виртуальную машину можно смигрировать не только между хостами, но и хранилищами средствами технологии Storage Live Migration.
Хосты, находящиеся в режиме обслуживания (maintenance mode) исключаются из механизма Dynamic Optimization.
А так настройка окна Power Optimization:
Все очень просто - ночью нагрузка спадает и можно смигрировать виртуальные машины с некоторых хостов, а сами хосты выключить. Потом окно заканчивается (начинается рабочий день) - хосты включаются, виртуальные машины переезжают на них, а Power Optimization не вмешивается.
Таким образом, получается, что Dynamic Optimization и Power Optimization в System Center Virtual Machine Manager 2012 представляют собой аналог VMware DRS и sDRS, что будет очень приятным моментом при использовании SC VMM 2012 с Hyper-V 3.0. И напоследок отметим, что функции Dynamic Optimization и Power Optimization в VMM 2012 работают при управлении не только хостами Hyper-V, но и платформами VMware vSphere и Citrix XenServer.
Но все же отличие Dynamic Optimization от VMware DRS есть - для Dynamic Optimization нельзя задавать Anti-affinity rules, что может оказаться некоторым неудобством для администраторов.
Мы уже много писали о решении для виртуализации настольных ПК предприятия - VMware View 5, эти записи можно просто найти у нас по тегу View. Там же можно найти заметки о некоторых бесплатных утилитах для VMware View. Сегодня мы рассмотрим очередную порцию бесплатных программ, некоторые из которых могут оказаться вам полезными при администрировании десктопов.
Это виртуальный модуль (Virtual Appliance) для Citrix Xenserver and VMware vSphere, обладающий той же самой функциональностью, что и стандартное издание NetScaler, но с ограничением 5 Мбит по полосе пропускания (есть и другие ограничения, например, число SSL-соединений). Надо отметить, что NetScaler умеет делать не только балансировку, но в данном случае он нам интересен именно как балансировщик. Ставится он вот сюда:
Кому интересно, как это работает, просим проследовать сюда.
Эта утилита от компании Quest Software имеет в своем арсенале 40 базовых оптимизаций для гостевой ОС виртуальной машины, которая становится "золотым" образом для развертываемых из него виртуальных ПК.
Все опитимизации имеют комментарии и рекомендации по тому, как эти настройки нужно выставлять. Кроме того, имеется Command Line для пакетного исполнения без GUI в шаблонах. Штука в хозяйстве полезная.
Эта утилита может понадобиться тем, кто хочет кастомизировать веб-портал VMware View, через который пользователи получают доступ к своим виртуальным ПК.
Тут можно настроить оповещения, ссылки, информацию о поддержке и т.п. Все это поставляется с админ-панелью.
Опять-таки, бесплатная утилита от Quest, позволяющая провести обследование текущей инфраструктуры предприятия на предмет консолидации виртуальных ПК в инфраструктуре VMware View.
Поставляется этот продукт как виртуальный модуль для VMware vSphere или Microsoft Hyper-V. Он определяет какие пользователи подходят для Hosted VDI, какие для Offline-десктопов, а какие для терминальных решений или виртуализации приложений. Ну и, естественно, выдает рекомендации по необходимому объему ресурсов для консолидации виртуальных ПК. Бесплатна, но ключ действует 5 дней.
Эта утилита уже не для виртуальных десктопов VMware View, а для решения ThinApp, которое в VMware View входит. Она позволяет просматривать содержимое виртуализованных пакетов ThinApp и анализировать его компоненты (виртуальная файловая система, реестр), а также опции, заданные при его создании.
Знаете еще интересные утилиты для VMware View? Пишите в каменты.
Также читайте наши заметки о бесплатных утилитах для VMware View:
Компания StarWind продолжает развивать партнерскую сеть и развиваться сама:
Компания Systematika недавно присоединилась к партнерской сети StarWind Global Distribution Network
Берлингтон, штат Массачусетс – 19 марта, 2012 - StarWind Software Inc., разработчик инновационного программного обеспечения для построения СХД и резервного копирования виртуальных машин, сегодня объявила о присоединении компании Systematika Distribution к международной партнерской сети StarWind. Компания Systematika, которая в Италии является лидером среди дистрибьюторов в области виртуальных технологий, добавила в свое портфолио программные продукты от StarWind. Теперь программное обеспечение StarWind будет распространяться через обширную сеть торговых представителей Systematika на эксклюзивной основе.
"Компания StarWind пополнила наше портфолио высококачественными и доступными по цене решениями СХД. Продукты этой компании представляют идеальное сочетание производительности, простоты и функциональности, и обеспечивают превосходную защиту данных. Мы думаем, что эти качества будут чрезвычайно интересными и выгодными для наших клиентов. Мы рассчитываем на длительное и успешное сотрудничество", - говорит Франко Пуричелли (Franco Puricelli), менеджер по продажам и развитию бизнеса компании Systematika Distribution.
"Мы очень рады сотрудничеству с Systematika Distribution, признанным лидером рынка виртуализации в Италии. Ведь правильный подбор партнеров очень важен для нашего бизнеса", - говорит Артем Берман, генеральный директор компании StarWind Software. "Мы уверены, что наши продукты будут иметь успех у клиентов Systematika, особенно в секторе малого и среднего бизнеса. Это однозначно поспособствует укреплению наших позиций на рынке".
Support for new processors – ESXi 5.0 Update 1 поддерживает новые процессоры AMD и Intel, которые приведены в VMware Compatibility Guide.
Support for additional guest operating systems – В ESXi 5.0 Update 1 появилась поддержка гостевых ОС Mac OS X Server Lion 10.7.2 и 10.7.3.
New or upgraded device drivers – В ESXi 5.0 Update 1 появилась поддержка драйверов Native Storage Drivers для чипсетов Intel C600 series, а драйвер LSI MegaRAID SAS продвинулся до версии 5.34.
Также были исправлены несколько зафикисрованных ранее проблем.
Новые возможности VMware vCenter 5.0 Update 1:
Улучшения механизма Guest Operating System Customization. Теперь vCenter Server может кастомизировать при развертывании следующие ОС:
Windows 8
Ubuntu 11.10
Ubuntu 11.04
Ubuntu 10.10
Ubuntu 10.04 LTS
SUSE Linux Enterprise Server 11 SP2
Кроме того, прошло массовое обновление следующих продуктов VMware:
Возможность Forced Failover, которая позволяет восстановление ВМ в случаях, когда дисковый массив отказывает на защищенном сайте, который ранее не мог остановить и разрегистрировать ВМ.
IP customization для некоторых релизов Ubuntu
Вернулась расширенная настройка storageProvider.hostRescanCnt (см. тут)
Массивы, сертифицированные на версии 5.0 автоматически пересертифицированы на 5.0.1
Обновленные версии VMware View Connection Server 5.0.1, который включает replica server, security server и View Transfer Server, а также VMware View Agent 5.0.1, VMware View Client for Windows 5.0.1
View Client for Mac OS X теперь поддерживает коммуникацию с виртуальными ПК по PCoIP (см. тут)
VMware View Client for Ubuntu Linux1.4 с поддержкой PCoIP
Новые релизы View client for Android и View Client for iPad (все клиенты View теперь консолидированно качаются тут)
Требование по наличию SSL-сертификатов со стороны клиента
И отметим, что VMware vSphere 5 Update 1 несовместима с некоторыми другими еще не обновленными продуктами VMware (наприме, Data Recovery 2.0). Поэтому вам может оказаться полезной следующая картинка совместимости от Джейсона:
Продолжаем вас знакомить с решением номер 1 для создания отказоустойчивых хранилищ виртуальных машин для серверов VMware vSphere 5 - StarWind iSCSI Enterprise. Блоггер Jake Rutski провел интересное тестирование, в котором он сравнил производительность продуктов StarWind iSCSI Enterprise и Microsoft iSCSI при работе виртуальных машин с хранилищами. Итак, характеристика тестового окружения...
Масштабируемость корпоративного класса, передовые возможности репликации, поддержка нескольких гипервизоров и принципиально новые возможности защиты данных в новом решении Veeam версии 6. Во время вебинара мы расскажем вам о других дополнениях этой версии, отмеченной многочисленными наградами. Таги:
Если вам хочется поддержать компанию StarWind Software, выпускающую лучшие решения для создания отказоустойчивых кластеров хранилищ VMware vSphere и Microsoft Hyper-V, номинируйте ее продукты на сайте премии Storage Awards 2012:
Наши друзья из Киева будут очень вам благодарны, если вы укажете продукты StarWind iSCSI SAN или StarWind Native SAN for Hyper-V в следующих категориях (в других не надо):
"Storage Virtualization Product of the Year"
"Storage Product of the Year"
"Storage Company of the Year"
Чтобы узнать, чем хороши приведенные выше продукты, можно почитать следующие статьи:
Решение номер 1 - StarWind iSCSI SAN - для создания отказоустойчивых хранищ под виртуальные машины серверов VMware ESXi и Microsoft Hyper-V снова в продаже со скидками, которые уменьшаются каждый день. Торопитесь!
Календарь скидок в процентах при заказе в первых двух неделях марта:

 RSS
RSS